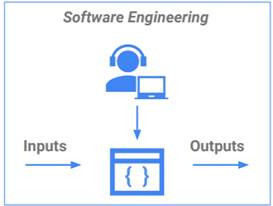
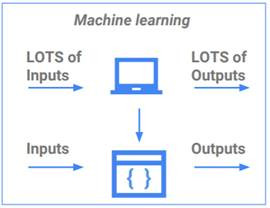
講了這麼多例子如果還有人不懂ML在幹嘛的也沒關係,接下來用下面兩張圖來做解釋,以前沒有ML的時候我們要怎麼達到想要的結果呢?當然是叫底下工程師開始寫Function啊………,但有了ML之後這些複雜的流程簡化成一個模型就好了,假設今天的工作是需要重複性質很高的工作,那為什麼不把它變自動化呢?更高級一點我叫機器跟我講現在要自動化囉,就像你今天請了一個機器人幫你打理大小事,從一天的一開始叫你起床→幫你做早餐→幫你叫車去上學…等例行性工作,讓你有其他時間可以去做更多可能機器做不到的事,這就是機器學習的真諦呀!
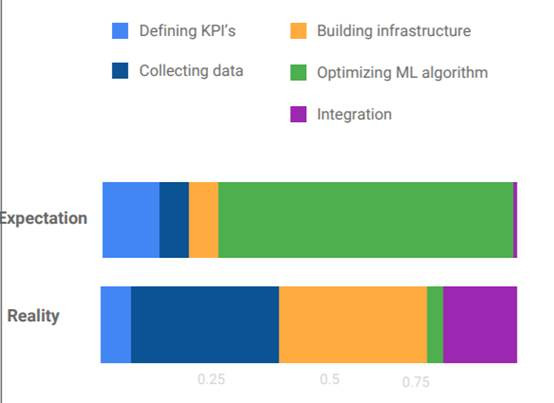
接著來聊聊許多人在建置ML常犯的錯誤吧,從開始到結束大概會有五個步驟需要去規劃,第一就是訂定你的KPI想要做甚麼事達到甚麼結果,第二就是根據你訂定的KPI來進行資料的蒐集,第三是建置你的基礎架構要用甚麼方式來完成,第四是優化ML的演算法,最後就是整合所有相關資訊。
但很多人的想法都是我模型建好了這些數據跟模型架構本身不會有問題,有問題的是甚麼?是我使用的演算法啦,因為演算法不夠強所以才沒有辦法把結果輸出,所以綠色這段變得非常的長在整個規劃的時間中;但實際上我們應該是要去檢查的是我們蒐集的資料是否為正確、模型架構是不是符合我們的問題才對,所以我們應該去壓縮修改更好更棒的演算法來提升整體的工作效率。
這裡整理出來10種在進行ML的時候可能會落入的陷阱。其中有四項都包含資料的部分,可想而知資料是多麼重要的,上述常見的錯誤前五名不外乎因為ML比較好為改而改的介面、以及我想做ML但我沒數據、我有數據但並不是我了解的或未處理、沒有專人去處理拿到的資料、專注於ML演算法的開發…等常見錯誤。
最後的最後,我們來談論如何真正建構一套ML模型吧
※圖片參考至 How Google does Machine Learning resource